svm_python_learn
svm_python_classify
svmapi Extension ModuleSVMpython is a Python embedded version of SVMstruct. One applies SVMstruct by modifying the svm_struct_api.c file and recompiling. SVMpython allows one to write these functions in Python instead: one applies SVMpython by creating a Python module (commonly just a .py file) with the appropriate methods. This module is loaded and specific methods called at runtime to support the structural learning algorithm.
One advantage of this Python embedding is this obviates many of the tedious non-learning-related maintenance procedures, allowing one to focus purely on the learning problem. The two most conspicuous examples are memory management, and reading and writing models to files (accomplished with Pickling). The primary disadvantage to using SVMpython is that it is slower than equivalent C code.
This code has a license. See LICENSE.txt and LICENSE-SVMPYTHON.txt in the distribution archive you get when downloading the software for more information.
http://tfinley.net/software/svmpython2/svm-python-v204.tgz.
make should work. (The exception is if the Python interpreter you get when you get python is the Python you wish to build against. Modify the PYTHON variable in Makefile to use a different Python.)
If successful, the program will produce two executables, svm_python_learn for learning a model and svm_python_classify for classification with a learned model.
I have tried building SVMpython with both Python 2.3, 2.4, and 2.5 on OS X and Linux. Obviously, what Python features you can use in your module depend upon which Python version you build against.
Invoking SVMpython is like SVMstruct: the same basic command line arguments are used in both varieties. The major difference is how to tell SVMpython what Python module to read.
Suppose you've written a Python module in the file foo.py and you want to use SVMpython with this foo module. The learn and classify executables try to determine the module to use with these steps in order:
--m foo (here, foo is the module name).
Looking for the module name in the environment variable SVMPYTHON_MODULE.
Using the default module svmstruct. (This default may be changed by changing the DEFAULT_MODULE := svmstruct assignment to something else, and rebuilding.)
Structural SVM learning is a framework for learning functions with complex structured outputs. One adapts this framework by providing functions specific to their particular task. SVMpython calls functions from the determined module. Consequently, developing an SVMpython module involves writing a module with functions of the desired behavior.
The file svmstruct.py is a Python module, and also contains documentation on all the functions which the C code may attempt to call. The multiclass.py file is an example implementation of multiclass classification in Python.
svm_python_learn
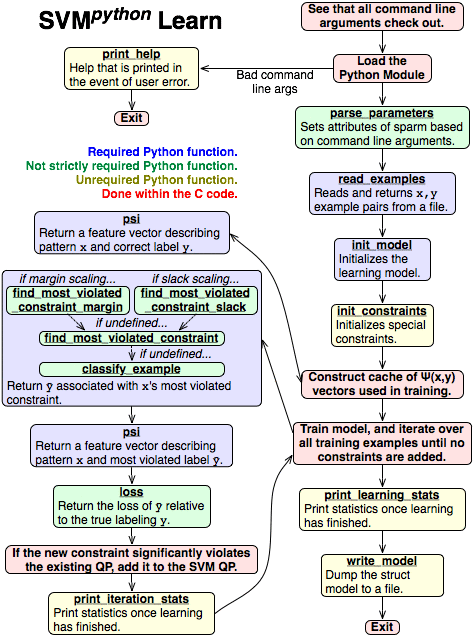
Pictured is a diagram illustrating the flow of execution within svm_python_learn. (This also describes the SVMstruct learning program pretty well.) Click on any functional box to see more in depth information for that function.
The red boxes indicate important processes in the underlying C code. Other boxes indicate Python functions implemented in the user's module. The blue boxes indicate functions that must be implemented. The green boxes and yellow boxes indicate functions that have some default behavior if they are not implemented, with green indicating that you probably want to implement this and yellow indicating functions whose default behavior is probably acceptable.
The svm_python_learn program first checks command line argument correctness, and attempts to load the user's Python module. If arguments were malformed, print_help is called and the program exits. Otherwise, learning model parameters are set with parse_parameters pattern-label example pairs are read with read_examples, user defined special constriaint initialized with init_constraints, the learning model initialized with init_model, the cache of all Ψ(xi,yi) combined feature vectors created with calls to psi, and then the learning process begins.
This learning process repeatedly iterates over all examples. For each example, the label associated with the most violated constraint for the pattern is found (using either find_most_violated_constraint_margin or slack, or if not found just find_most_violated_constraint, or if that was not found classify_example). Then, the feature vector Ψ describing the relationship between the pattern and the label is computed with psi, and the loss Δ is computed with loss. The program determines from Ψ and Δ whether the constraint is violated enough to add it to the model. The program moves on to the next example. At various times (which depend on options set) the program retrains, whereupon print_iteration_stats is called. In the event that no constraints were added in an iteration, the algorithm either lowers its tolerance or, if minimum tolerance has been reached, ends the learning process.
Once learning has finished, statistics related to learning may be printed out with print_learning_stats, the model is written to a file with write_model, and the program exits.
svm_python_classify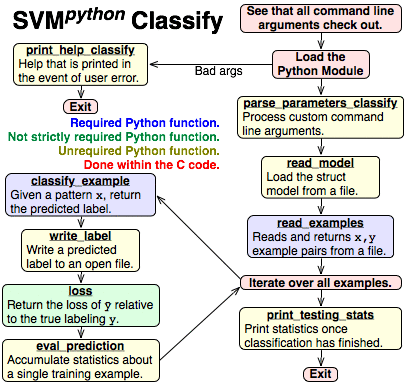
Pictured is a diagram illustrating the flow of execution within svm_python_classify. The color coding of the boxes is the same as that in the high level description of the learning program.
The svm_python_classify program first checks whether the command line arguments are fine and loads the user module. If the arguments are malformed the program calls print_help_classify and exits. Otherwise, custom parameters are processed with calls to parse_parameters_classify for each custom parameter. Then, the learned model is read with read_model and the testing pattern-label example pairs are loaded with read_examples. Then, it iterates over all the testing examples, classifies each example, writes the label to a file, finding the loss of this example, and then may evaluate the prediction and accumulate statistics, with classify_example, write_label, loss, and eval_prediction respectively. Once each example is processed, some summary statistics are printed out with print_testing_stats and the program exits.
svmapi Extension ModuleSVMpython provides an extension svmapi module. This extension module provides many of the basic types that the user module accepts as inputs (and occassionally provides as outputs). To gain access to the contents of this module, you must import the module svmapi. Read the documentation for more information.
Critical portions of this module are Sparse objects (sparse vector objects, returned from psi) and StructModel objects (to set the size_psi attribute in init_model, the w attribute for inference when you have a linear model, the classify convenience method, and assigning attributes to be serialized/deserialized when writing the model).
Also included are many functions that have the default behavior.
In addition to this documentation, you can see the source code for the svmstruct.py module and its documentation which contains instances and a basic synopsis of all the functions SVMpython calls, a multiclass.py module which implements a multi-class SVM (training and testing inputs contained in multi-example in the SVMpython distribution), as well as the svmapi extension module documentation.
There was another version of SVMpython that came out in early 2005. This is SVMpython 2, which came out mid 2007. This is different in many internal respects largely invisible to the user. Key differences include:
svmapi instead of svmlight, and the internal objects and structures differ.
struct in their names typically have struct removed, e.g., what was read_struct_examples is now just read_examples.
-w option).